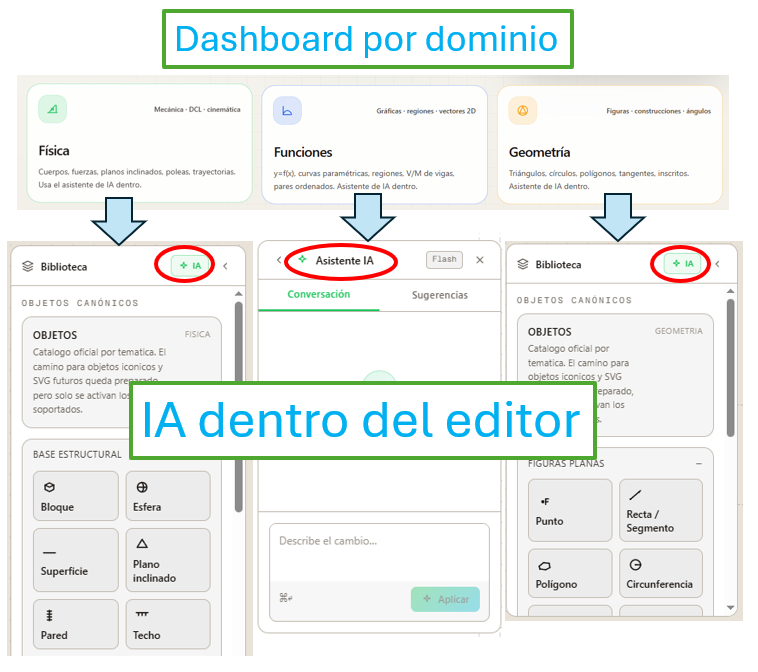
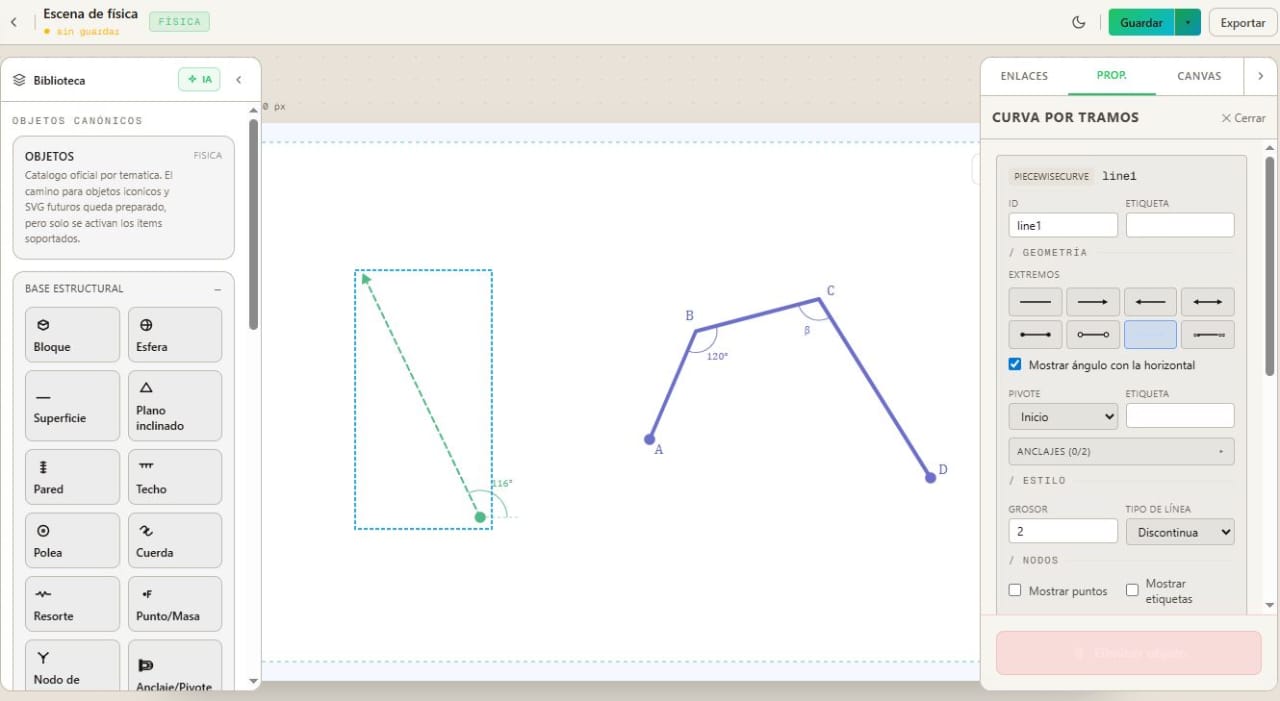
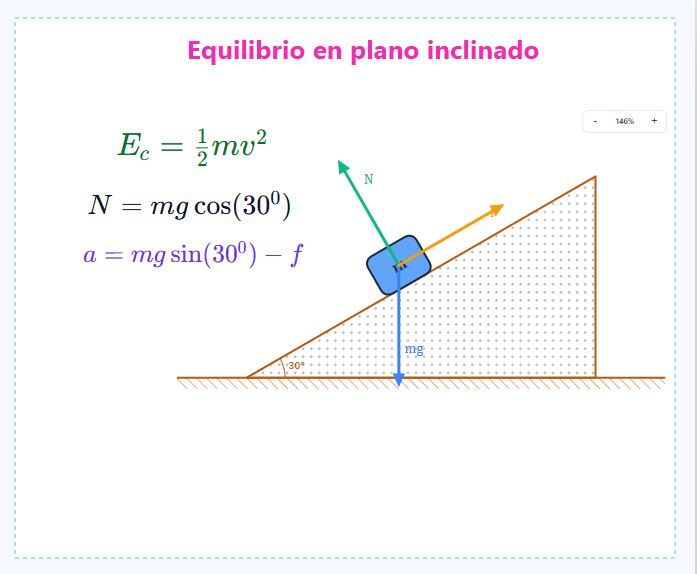
Plano inclinado: descomposición y ejes opcionales en el template
La plantilla pública "bloque en plano inclinado" ganó dos controles que el docente puede activar por paso o por escena. El primero muestra las componentes del peso paralela y perpendicular al plano, etiquetadas con la fórmula y el ángulo real (Fg·sen(30°), Fg·cos(30°)), descompuestas por el solver desde el peso vertical — actualizan automáticamente con el slider del ángulo. El segundo dibuja un sistema de ejes XY anclado al centro del bloque, que rota con el plano para que el alumno vea explícitamente el sistema de referencia rotado en el que se hace la descomposición. Los dos controles son independientes: ejes solos para introducir el sistema de referencia, componentes solas para mostrar la descomposición clásica de textbook, o ambos juntos para conectarlos visualmente. La normal cambia de longitud con el ángulo siguiendo la relación de equilibrio (a θ=60° la normal mide la mitad del peso): el diagrama es cuantitativamente medible con regla, no solo cualitativo.
En la versión anterior la plantilla solo tenía peso, normal y un toggle de "componentes" que dibujaba dos flechas con direcciones aproximadas. Ahora la descomposición la genera el mismo solver que usa el editor cuando se arma una escena con un sistema de coordenadas en modo "auto tangente": el mismo mecanismo, una sola fuente de verdad. El resultado es que la plantilla curada queda idéntica a lo que un creador armaría en el editor con los mismos elementos, sin ramas paralelas que divergen con cada cambio. Para soportar el caso pedagógico, además, se hizo configurable el rótulo de las componentes desde cualquier escena: por defecto el solver las llama mg_t y mg_n, pero el autor puede pedir la fórmula con el ángulo real (Fg·sen(θ°)) o el símbolo que prefiera, sin que eso sea un parche por plantilla. Mismo razonamiento aplicado al color: las componentes heredan el del peso para que se lean como su descomposición, no como fuerzas nuevas.